This blog will introduce two key best practices for optimizing AIE designs: C/C++ techniques for enhancing run-time performance and a hierarchical design setup. These practices are crucial for creating high-performance and maintainable AIE designs.
Versal is the latest generation of AMD FPGA offerings built on the TSMC 7nm FinFET process technology. Versal Adaptive SoCs represent a significant advancement in FPGA technology with their impressive architecture and outstanding capabilities. The integration of the Processing System (PS), Programmable Logic (PL), and AI Engine (AIE) interconnected by a high-bandwidth Network-on-Chip (NoC) offers a versatile and powerful platform to build a wide range of AI and DSP applications. For a deeper dive into the Versal platform’s architecture and capabilities, check out our comprehensive guide: Versal FPGA Platform: A Comprehensive Guide.
A key highlight of Versal Adaptive SoCs is the AI Engine (AIE), designed to handle complex computations efficiently. Featuring a 2D array of VLIW (Very Long Instruction Word) and SIMD (Single Instruction Multiple Data) vector processors (compute tiles), the AIE can contain up to 400 compute tiles in a single Versal device. This architecture offers impressive throughput and latency performance, making it an ideal solution for AI and DSP tasks.
C/C++ Techniques for Boosting Run-time Performance
This section discusses the use of C/C++ features to enhance the run-time performance with compile-time optimizations.
Using inline functions
It is a simple technique to optimize performance. By declaring functions as inline, you can eliminate the overhead associated with function calls, which is particularly beneficial for small and frequently called functions. This can lead to faster execution times and more efficient use of resources. Here’s a simple inline example in C/C++:
In this example, the add function is defined as inline, which instructs the compiler to insert the function’s code directly at the point of each call, rather than performing a traditional function call . Note that using inline functions may lead to a larger register consumption and an increase of the size of the program, It may not be efficient unless the functions to be inlined are short.
Using constexpr specifiers
This will enable the evaluations of variables and functions at compile-time. It is a great technique to enhance run-time performance by shifting numerical calculations from run-time to compile-time. Here’s a simple example of using constexpr in C/C++:
In this case, when you make a square(8) function call, it is evaluated at compile-time and the result (64) is directly embedded in the code, eliminating the need for a function call to calculate the result at run-time. Since the compiler does the calculations at compile-time, there isn’t any cost at run-time, saving precious AIE cycles for computations that need to be done at run-time. The technique also applies to templated functions.
Templates and “if constexpr”
Templates combined with the “if constexpr” construct provides a powerful one-two punch for writing generic, reusable, and efficient kernel code which can parameterize types and values, making your kernel code more adaptable to different data types and configurations without duplicating code.
The “if constexpr” construct enables compile-time decision-making to control the flow of code execution. When a kernel is instantiated, the compiler evaluates the “if constexpr” constructs. Depending on the evaluation result, it will decide which functions to be included for compilation and render all irrelevant code branches to be excluded at compile-time.
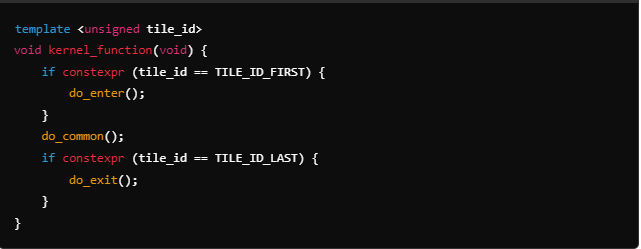
This approach ensures that only the necessary code is compiled and executed, leading to optimized executables and increased performance at run-time. Here a simple example of using a template and the “if constexpr” construct to write generic and efficient kernel code in a multi-tile AIE design:
In this example, the tile_id is parameterized, making the kernel function adaptable to different tiles without duplicating code. As instructed by the if constexpr constructs, the do_enter() and do_common() functions will be included and compiled for the first kernel, the do_common() and do_exit() functions for the last kernel, and the do_common() function only for all other kernels. Since all the if constexpr constructs are evaluated at compile-time, there is no code branching at run-time.
Restrict keyword
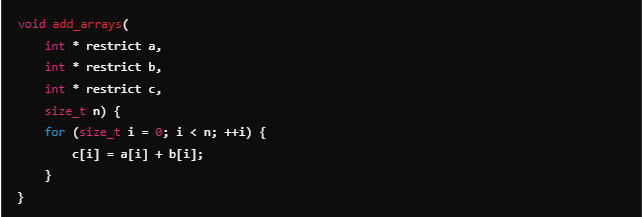
The restrict keyword in C/C++ is another powerful tool for optimization. When you declare a pointer with restrict, you’re telling the compiler that this pointer is the only way to access the object it points to. This allows the compiler to make more aggressive optimizations that it could not safely make otherwise, because it can assume that no other pointer will modify the object. Pointer aliasing refers to scenarios in which the same memory location can be accessed by different pointers. The strict no-aliasing rule applies when the restrict keyword is used. Here is a simple example of using the restrict keyword:
In this function, the compiler knows that a, b, and c point to separate memory locations, allowing it to optimize the loop more aggressively.
Hierarchical Design Setup for Maximizing Efficiency and Maintainability
The “Divide and Conquer” strategy is a powerful approach when implementing complex data processing algorithms in AIE. This approach streamlines development, debugging, and testing, making your AIE development more efficient and manageable. By breaking down the algorithm into smaller and manageable building blocks, you can focus on developing and optimizing each component individually. Once all individual blocks are functioning correctly and meeting the performance targets, you can then integrate them to form the complete system.
This method not only simplifies the development process, but also makes debugging and testing more efficient. If an issue arises, you can isolate it to a specific block rather than sifting through the entire algorithm. In addition, running AIE simulations for a single block is much faster than running simulations for the entire system. Another benefit of this modular approach is to facilitate the reuse of individual blocks across different projects to save time and effort. Lastly, it allows easier updates and scalability, as you can modify or replace individual blocks without overhauling the entire system.
A detailed description of the methodology of setting up a two-level hierarchy in AIE designs is the followings:
Block-Level Design
Foundation Level: This is where each individual block is defined. Each block is responsible for implementing a specific functionality or a set of related functions. For instance, one block might handle data input, another might process the data, and a third might handle data output.
Implementation: Focus on developing and optimizing each block independently. Ensure that each block meets its performance targets and functions correctly before moving on to the next.
Top-Level Design
Aggregation: This level involves stitching together all the blocks into a cohesive system.
Integration: Ensure that the blocks interact seamlessly and that data flows smoothly between them. This might involve setting up communication protocols, managing data dependencies, and handling any synchronization issues.
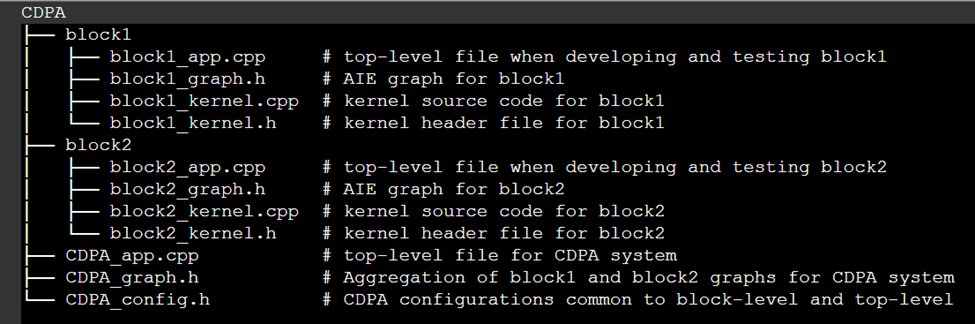
Here is a simplified example to demonstrate the directory setup of a two-level hierarchy in an AIE design called CDPA (Complex Data Processing Algorithm):
The above annotated screen capture illustrates a hierarchical setup to facilitate block-level development and top-level integration in AIE designs.
Conclusion
This blog introduces a few best practices in AIE designs. By following these best practices, you will be able to create AIE designs that are not only efficient and high-performing but also scalable and easy to maintain.
At Fidus, we bring decades of experience in FPGA design and embedded systems development. Our team has worked across industries, including telecommunications, aerospace, defense, and consumer electronics, delivering customized solutions tailored to meet specific project requirements. We understand the complexities involved in integrating FPGAs into embedded systems and have the expertise to ensure optimal performance and reliability.
Optimize FPGA Designs with AMD Versal Adaptive SoCs
Want to learn more about optimizing Versal AI designs? Watch our on-demand webinar: Strategies for Optimizing FPGA Designs with AMD Versal Adaptive SoCs. This session explores techniques for efficient data movement using NoC, CIPS, DFX, and AI Engines, as well as optimizing transfer speeds for high-performance systems.
The Engineering Capacity Playbook: When, Why, and How to Scale With Embedded Design Expertise
Engineering leaders are under increasing pressure to deliver more complex systems with fewer internal resources. FPGA logic grows more demanding, embedded software expands faster than teams can staff, and board level designs now require deeper integration across hardware and firmware. This playbook gives leaders a clear framework for understanding when external engineering support becomes essential, how to choose an engagement model that protects quality and schedule, and what separates productive collaborations from the ones that create risk. Drawing on lessons from hundreds of advanced development programs, it outlines how to scale engineering capacity without slowing execution or sacrificing control.
What to Expect When Partnering with an Embedded Systems Design Services Company
Hardware doesn’t move at software speed — and that’s okay. Here’s what decision-makers need to know about realistic timelines when partnering with an embedded systems design services company like Fidus.
Hardware-Based Security for Embedded Systems: Exploring Trusted Platform Modules (TPMs)
As embedded systems become more connected and exposed to cyber threats, software-only security is no longer enough. Trusted Platform Modules (TPMs) provide a hardware root of trust that anchors device integrity, safeguards cryptographic keys, and enables secure boot processes. This blog explores how TPMs strengthen embedded systems, from their core architecture and advanced features to real-world applications in automotive, industrial, and IoT devices — and what engineers must consider to future-proof TPM security against emerging threats.